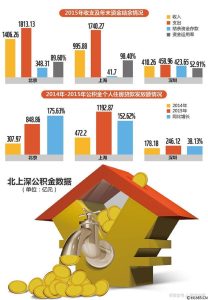
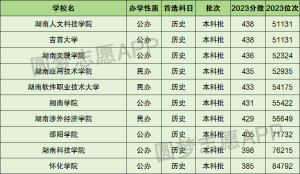
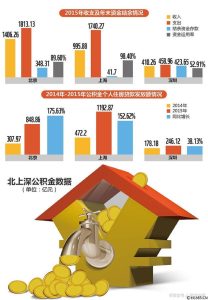
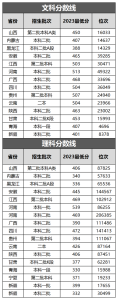
文章目录
F12开发者模式
打开谷歌浏览器,F12进入后观察network部分
如何找到network中我们需要的部分
如果是按F5刷新才出来的,一般在DOC里面
如果是点击按钮加载更多,请求在XHR里面

如何验证请求正确

复制页面上的字,在response里ctrl+F查找,能找到说明找对了位置
模拟发送

找到 url 方法以及 header

从 accept 到 user-agent 全都要,cookie 在程序中可以写空

首字母大写,逗号连接
requests_headers = { 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'Accept-encoding': 'gzip, deflate, br', 'Accept-language': 'zh-CN,zh;q=0.9', 'Cache-control':'max-age=0', 'Cookie': '', 'Referer': 'https://www.zhihu.com/search?q=vczh&type=content', 'Upgrade-insecure-requests': '1', 'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' } url = 'https://www.zhihu.com/topic/20004648/hot' z = requests.get(url, headers=requests_headers) print(z.content) hea
原文链接:https://blog.csdn.net/manong_dashen/article/details/118163886?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171910925216800178568569%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171910925216800178568569&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~times_rank-8-118163886-null-null.nonecase&utm_term=2024%E9%AB%98%E8%80%83%E6%9F%A5%E5%88%86
© 版权声明
声明📢本站内容均来自互联网,归原创作者所有,如有侵权必删除。
本站文章皆由CC-4.0协议发布,如无来源则为原创,转载请注明出处。
THE END